Lecture 4 · Model-free prediction
These are the notes taken during the RL Course by David Silver.
Lecture 4 · Model-free predictionIntroductionMonte-Carlo learningFirst-visit Monte-Carlo policy evaluationEvery-visit Monte-Carlo policy evaluationIncremental Monte-Carlo updatesTemporal Difference learningMC and TD learningAdvantages and disadvantagesBias-variance trade-offBatch MC and TDCertainty equivalenceMarkov propertyBootstrapping and samplingTD()-returnEligibility traceBackward view TD()
Introduction
In the last lecture we worked assuming that we knew a model of the environment. Now we will not assume this. In this lecture we aim to predict the value of a given policy if we don't know how the environment works.
Monte-Carlo learning
These methods learn directly from experience.
We use complete episodes to learn. A caveat is that all episodes must terminate.
MC assumes that value = mean return. We replace the expectations by the mean.
First-visit Monte-Carlo policy evaluation
To evaluate state , at the first time-step that is visited in an episode:
- We increment the counter
- We increment the total return
- We can now compute the mean return
By the law of large numbers, approaches the true value function as .
Every-visit Monte-Carlo policy evaluation
In this case, we consider every visit to state to estimate the value. All the other ideas and steps are the same.
In this way, we could increment the counter several times in the same episode.
Incremental Monte-Carlo updates
Incremental mean: The mean can be computed incrementally: . This result can be easily obtained by separating into two parts.
We can incrementally update the mean in a MC learning scenario in a similar way:
In non-stationary problems, we can track a running mean to forget old episodes: .
Temporal Difference learning
TD methods learn from actual experience, like MC methods.
The difference is that TD can learn from incomplete episodes, by bootstrapping.
Bootstrapping: making a guess towards a guess.
MC and TD learning
If we take the incremental Monte-Carlo update equation: ,
And then replace the average return by the estimated return , also called the TD target
We obtain TD(0):
is called the TD error
Advantages and disadvantages
- TD can learn before seeing the final outcome. MC must wait until the end of the episode.
- TD can learn in situations when you don't see the final outcome. MC doesn't apply here.
Bias-variance trade-off
The return is unbiased estimate of
The true TD target is unbiased estimate of
TD target is biased estimate of
However, TD target is much lower variance than the return, because the return depends on many random actions, rewards... whereas the TD target depends only on one random action, reward...
MC has high variance, zero bias
- good convergence
- not sensitive to initial value
TD has low variance, some bias
- usually more efficient than MC
- not always converges with function approximation
- more sensitive to initial value
Batch MC and TD
What if the experience was finite? Do these algorithms converge given a finite batch of experience?
Certainty equivalence
- MC converges to solution with minimum mean-squared error.
- TD(0) converges to solution of max likelihood Markov model: the solution to the MDP that best fits the data.
Markov property
- TD exploits the Markov property, therefore being more efficient in Markov environments
- MC doesn't exploit Markov property, usually more effective in non-Markov environments
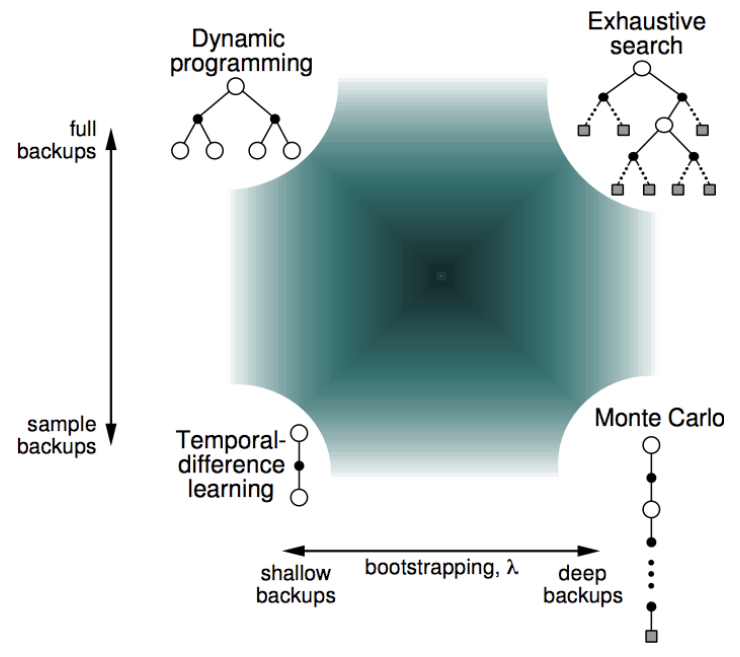
Bootstrapping and sampling
Several techniques to estimate the value fucntion:
Bootstrapping: update involves an estimate
- MC doesn't bootstrap
- TD bootstraps
- DP bootstraps
Sampling: update uses an expectation
- MC samples
- TD samples
- DP doesn't sample
TD()
The choice of the algorithm is not either TD or MC. There is in fact a family of algorithms that lie between these two cases, and contain both TD(0) and MC as specific cases.

We can obtain this using n-step returns.
Define the n-step return:
n-step temporal-difference learning:
Averaging n-step returns: We can average n-step returns with different n (e.g. average 2-step and 4-step returns)
-return
TD() combines all n-step returns by weighting them
Update:
This is called forward TD(), because of the looking forward towards the future.
Eligibility trace
An eligibility trace combines both the frequency heuristic and recency heuristic (that say that an event must occur based on the times we've seen something or the recency of us seeing that)
Backward view TD()
- We keep an eligibility trace for every state
- We update the value for every state
- Every update is performed in proportion to TD-error and eligibility trace:
When , we only update the current state: equivalent to TD(0)
Theorem:
The sum of offline updates is identical for forward and backward-view TD()
The equality can be proved .
This result has been extended to online updates as well.